阅读:0
听报道
主持人:巴曙松
主讲人:李叶
今天,我主讲的题目是超越线性回归——在大数据时代下的量化金融,选这个标题的主要原因是华人在华尔街一般都是从事量化的工作,且在当前形势之下,大数据云技术是一个非常热门的话题。
一、关键词

首先讲一些关键词,这些关键词代表着一个很大时间尺度下的公共环境和哲学思维,其实这些思维已经在技术实施当中逐渐体现了。从个人来看,最重要的关键词应该是虚拟化。虚拟化从几千年以前就开始了,即货币。当货币发明之后,这个交易就某种程度上虚拟化。但是近来技术突飞猛进加速了虚拟化的过程,虚拟化发展到今天出现了趋中心化的趋势,这是因为虚拟化使得相关性无限的延伸。而这样的效果就使得中心化的弊端就慢慢的凸显出来。虚拟化还带来了一个结果,即容易产生赢者通吃的结果。虚拟化使得财富的积累,社会影响等产生两极分化,而且越来越重。其实这种思路也在技术上体现,比如说云技术、虚拟机。技术上的基础设施就是代码,而代码就是基础设施。趋中心化也就在技术上有些体现,比如说,我们现在有一种技术叫做集装箱。用多年前的旧思路来看,我们应用的开发时间非常长;在使用中我们希望有个中心的系统,一个修正可以惠及整个系统,使得我们所做的改变可以惠及整个公司或者整个行业。新的思路是什么?现在我们需要做的软件和应用大幅增多,使用寿命缩短,出错概率高,但我们要做的是让一个错误不要出现大面积的灾害。
二、量化金融

量化金融是数学在金融市场应用的一个领域。常见的例子就是衍生品定价,包括期权、期货与合约。量化金融在资产或者财务管理上也有一些例子,比如资产配置:Black-Littleman模型,其次是智能投顾。因为它的应用可能就在附近管理上需要用到许多量化金融。此外,量化金融也用在交易策略上,比如说如何去做事;如何寻找绝佳的交易途径;如何在高频、中高频、中频等交易中寻找逃离的机会。我们也用量化来预测宏观形势,预测消费者的行为等。量化金融关注的不是必然联系,而是随机过程和概率分布。从金融本质上来讲,如果没有不确定性就没有风险,如果没有风险就没有超额收益。生态化金融当中数据和数据分析是根本。
三、ABC浪潮

下面简单介绍一下大数据及大数据技术。我们常常说到ABC浪潮,即计算机程序所能模仿的人类智能,包括学习、感知、自然语言处理等。
大数据一般指的是由于量大、种类多、增长速度很快等特性,使得传统的工具无法处理。比如说采集、存储、分析、分享,查询、传输、保密等这类数据。它可以用配置的方式来快速实施系统资源共享模式,即基于基础设施就是代码,代码就是基础设施。云计算是现在通用大数据处理基础设施;人工智则是有效实现大数据价值的重要的途径。就机器学习而言,其高端部分主要归属于人工智能;其低端部分,比如回归,是传统的量化金融的一个重要组成部分。大数据往往是特指传统的结构化此外的数据,比如文本、图像、语音等,存储资源占用大,很有可能产生赢者通吃的效果,而这种赢者只需要比其他人强一点,早一点。
四、机器学习与量化金融
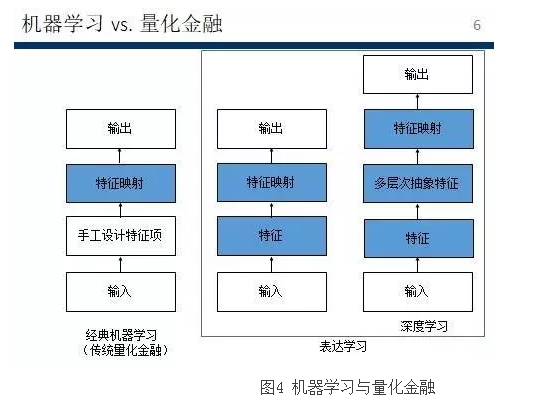
下面再介绍一下机器学习和量化金融之间的关系。上图是讲了机器学习的三个阶段。第一个阶段就是经典机器学习,跟我们的传统的量化金融有很大的重叠。这里有输入、输出,输入就是它的自变量,根据这些变量能得出什么样的结论。在建模型的时候,我们往往需要手工设置一些特征象,即需求。例如,我们欲知道消费者对利率的感应情况,找到其诱因,需要提前设计一些函数形式,把特征设计完后,映射到需要预测的变量。机器学习比较高端的部分为表达学习,其不需要手工设计特征项目,直接输入后就自动产生特征,特征在映射到模型当中去。

深度学习是把特征变成多个层级,从一开始简单的特征到多层次的成像的特征,再进行特征映射的激励模型。深度学习最经典的例子就是图像,我们的初始特征为像素。每个像素为一个不同颜色的点,不同的颜色使它产生边界,这种边界就会产生一些拐角并形成轮廓。这些轮廓可以产生一些部件,部件的组合就是个问题。这是用来往往需要解决人的直觉很容易解决的问题,但是用固化的逻辑程序解决难题。因此在我们在设计深度学习的时候,需要做大概念的提炼,这是非常艰难的。但是建立起来之后,我们只需要输给程序一道学习样本,表明哪些样本是我们的目标物体即可。
五、传统量化算法
现在与大家介绍一下传统量化算法,在传统的量化当中量化技术用了两个算法,一是logistics回归。关于logistics回归有几个重要概念,广义线性模型、关联函数和正则关联函数。logistics回归是假定事情的发生,服从伯努利分布,每个数据点输入变量,输出一个时间发生的预期概率。但是我们在使用logistics回归的时候往往会遇到一些困扰,其中一个巨大的困扰就是模型变量都是手工设计的,它需要很强的业务洞察力,而效果却没有保障。此外,不同变量的交叉作用项很难模拟。Logistics函数本身的特征(比如零点的斜率最大)产生出一些表象,却被很多从业者误以为是资产真正的行为。
第二个比较传统的一个算法叫主成份分析(PCA:Principle Component Analysis)。解读为抓住主要矛盾,放掉次要矛盾。针对所有的风险因子,根据历史数据或预测等,求出相关矩阵;求出相关矩阵的所有特征及相应的特征向量,并按特征值由小到大排列;特征值越大的特征向量也就是越重要的主要成分。以下使用几个案例进行辅助说明。例如研究房价指数,我们把房价分成一线城市、二线城市等;在量化投资中,我们可以用趋势跟踪,找到一个组合放大的波动性;文件压缩,例如我有一个较大的图像文件、语音文件或视频文件,如何在少量信息遗失的情况之下压缩文件大小,那么就可以使用主成份分析来来储存这些信息。
六、超越线性回归——现有着力点
在大数据的情形下如何将传统量化金融抬高一个台阶?以下是我的几点看法。第一,引入新的数据。传统的量化金融局限在传统数据上,还未引进新的数据。第二,创立全新的Feature Engineering的模式,避免手工设计变量。第三,提高现有模型的预测能力。第四,缩短模型开发周期。

这个产品是信用挂钩票据,在这个结构里面分了四个层级,A、M1、M2和B。以前看过的研究报纸往往是用一些非常传统的方式研究产品即使用行为模型,对其违约、早偿进行预测,根据结果估算M1、M2的定价。在业内不同公司的模型预测结果差距并不大,这种细微的差距都在模型误差之内,所以这种分析对模型定价没有任何指导意义。

上图是我在产品刚刚销售刚发起时所做的分析。根据市场交易的价格,反推出市场认为哪些贷款是房贷,它的预期的损失有多少。假定A没有损失,B损失100%,M1和M2额外收益抵消掉有可能产生的损失,这样可以大致算出这个产品的损失。再结合当时两房的担保费用(Guarantee Fee),可以得出若房贷不进行证券化将高出1.5%。从此处可看出两房是在获取暴利。这个结论引出几个疑问。第一,市场上有无套利原则,但它是明显的套利机会,为什么市场不去实现?在两房可以获得暴利的市场情况下,为什么Non-Agency MBS不能复活?第二,Basel III是否对信用风险和利率风险一视同仁?第三,银行的风险资本的计提方法对Non-Agency MBS有什么影响?第四,需要哪些数据来进行这些研究?
这就是超越线性回归需要引入更多数据的案例。
多数据都是非结构化数据,需要大数据手段,第二个可超越的点就是Feature Engineering,即如何能够用更好的框架来设计变量。Feature Engineering的目标是第一,减少甚至消灭人工设计以减少负担;第二,解决高阶项和交互项的难点,减弱甚至消灭极端情形下的illusion;第三,识别市场上的结构型变化。
第三个可超越点是提升现有模型的预测能力。Adaboost用中国的古话可理解为:三个臭皮匠赛过诸葛亮。即将一组预测能力较弱的模型组合成预测能力强的模型。其基本思路如下。首先,原先被预测错的样本在后续模型的训练中占更高的比重。其次,预测能力较强的模型话语权越高。Adaboost在分类算法中有较多的使用例子,但是如何运用到回归算法中去,是我们需要继续思考的问题。
第四个可超越点是缩短模型开发周期。利用云技术,例如Cloudera、spark,达到流程自动化,把人力用到更有意义的研究中。此外,不让存储、查询等能力的欠缺拖后腿。
主讲人简介
李叶:物理学博士,CFA,最早从事大数据领域的华人,随后在多家顶尖华尔街金融机构担任要职,归国后建立广发证券的数据治理中心及产品中心。
文章载于今日头条(2018年1月3日)
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}